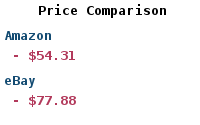Python Data Science Handbook
Essential Tools for Working with Data

Book Description
For many researchers, Python is a first-class tool mainly because of its libraries for storing, manipulating, and gaining insight from data. Several resources exist for individual pieces of this data science stack, but only with the Python Data Science Handbook do you get them all - IPython, NumPy, Pandas, Matplotlib, Scikit-Learn, and other related tools.Working scientists and data crunchers familiar with reading and writing Python code will find this comprehensive desk reference ideal for tackling day-to-day issues: manipulating, transforming, and cleaning data; visualizing different types of data; and using data to build statistical or machine learning models. Quite simply, this is the must-have reference for scientific computing in Python.
IPython and Jupyter: provide computational environments for data scientists using Python; NumPy: includes the ndarray for efficient storage and manipulation of dense data arrays in Python; Pandas: features the DataFrame for efficient storage and manipulation of labeled/columnar data in Python; Matplotlib: includes capabilities for a flexible range of data visualizations in Python; Scikit-Learn: for efficient and clean Python implementations of the most important and established machine learning algorithms.
Book Details | |
| Publisher: | O'Reilly Media |
| By: | Jake VanderPlas |
| ISBN-13: | 9781491912058 |
| ISBN-10: | 1491912057 |
| Year: | 2016 |
| Pages: | 541 |
| Language: | English |
Book Preview | |
| Online | Python Data Science Handbook |
Paper Book | |
| Buy: | Python Data Science Handbook |
Share Python Data Science Handbook