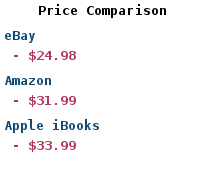Programming Hive
Data Warehouse and Query Language for Hadoop

Book Description
Need to move a relational database application to Hadoop? This comprehensive guide introduces you to Apache Hive, Hadoop's data warehouse infrastructure. You'll quickly learn how to use Hive's SQL dialect - HiveQL - to summarize, query, and analyze large datasets stored in Hadoop's distributed filesystem.This example-driven guide shows you how to set up and configure Hive in your environment, provides a detailed overview of Hadoop and MapReduce, and demonstrates how Hive works within the Hadoop ecosystem. You'll also find real-world case studies that describe how companies have used Hive to solve unique problems involving petabytes of data.
- Use Hive to create, alter, and drop databases, tables, views, functions, and indexes;
- Customize data formats and storage options, from files to external databases;
- Load and extract data from tables - and use queries, grouping, filtering, joining, and other conventional query methods;
- Gain best practices for creating user defined functions (UDFs);
- Learn Hive patterns you should use and anti-patterns you should avoid;
- Integrate Hive with other data processing programs;
- Use storage handlers for NoSQL databases and other datastores;
- Learn the pros and cons of running Hive on Amazon's Elastic MapReduce.
Book Details | |
| Publisher: | O'Reilly Media |
| By: | Edward Capriolo, Dean Wampler, Jason Rutherglen |
| ISBN-13: | 9781449319335 |
| ISBN-10: | 1449319335 |
| Year: | 2012 |
| Pages: | 352 |
| Language: | English |
Book Preview | |
| Online | Programming Hive |
Free Download | |
| Source Code | Programming Hive |
Paper Book | |
| Buy: | Programming Hive |
Share Programming Hive