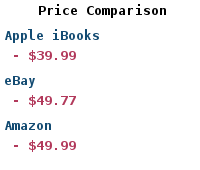Mastering Large Datasets with Python
Parallelize and Distribute Your Python Code

Book Description
Modern data science solutions need to be clean, easy to read, and scalable. In Mastering Large Datasets with Python, author J.T. Wolohan teaches you how to take a small project and scale it up using a functionally influenced approach to Python coding. You'll explore methods and built-in Python tools that lend themselves to clarity and scalability, like the high-performing parallelism method, as well as distributed technologies that allow for high data throughput. The abundant hands-on exercises in this practical tutorial will lock in these essential skills for any large-scale data science project.Programming techniques that work well on laptop-sized data can slow to a crawl - or fail altogether - when applied to massive files or distributed datasets. By mastering the powerful map and reduce paradigm, along with the Python-based tools that support it, you can write data-centric applications that scale efficiently without requiring codebase rewrites as your requirements change.
Mastering Large Datasets with Python teaches you to write code that can handle datasets of any size. You'll start with laptop-sized datasets that teach you to parallelize data analysis by breaking large tasks into smaller ones that can run simultaneously. You'll then scale those same programs to industrial-sized datasets on a cluster of cloud servers. With the map and reduce paradigm firmly in place, you'll explore tools like Hadoop and PySpark to efficiently process massive distributed datasets, speed up decision-making with machine learning, and simplify your data storage with AWS S3.
Book Details | |
| Publisher: | Manning |
| By: | John T. Wolohan |
| ISBN-13: | 9781617296239 |
| ISBN-10: | 1617296236 |
| Year: | 2020 |
| Pages: | 312 |
| Language: | English |
Book Preview | |
| Online | Mastering Large Datasets with Python |
Free Download | |
| Source Code | Mastering Large Datasets with Python |
Paper Book | |
| Buy: | Mastering Large Datasets with Python |
Share Mastering Large Datasets with Python