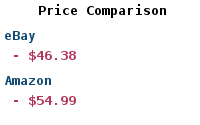Modern Data Engineering with Apache Spark
A Hands-On Guide for Building Mission-Critical Streaming Applications

Book Description
Leverage Apache Spark within a modern data engineering ecosystem. This hands-on guide will teach you how to write fully functional applications, follow industry best practices, and learn the rationale behind these decisions. With Apache Spark as the foundation, you will follow a step-by-step journey beginning with the basics of data ingestion, processing, and transformation, and ending up with an entire local data platform running Apache Spark, Apache Zeppelin, Apache Kafka, Redis, MySQL, Minio (S3), and Apache Airflow.Apache Spark applications solve a wide range of data problems from traditional data loading and processing to rich SQL-based analysis as well as complex machine learning workloads and even near real-time processing of streaming data. Spark fits well as a central foundation for any data engineering workload. This book will teach you to write interactive Spark applications using Apache Zeppelin notebooks, write and compile reusable applications and modules, and fully test both batch and streaming. You will also learn to containerize your applications using Docker and run and deploy your Spark applications using a variety of tools such as Apache Airflow, Docker and Kubernetes.
Reading this book will empower you to take advantage of Apache Spark to optimize your data pipelines and teach you to craft modular and testable Spark applications. You will create and deploy mission-critical streaming spark applications in a low-stress environment that paves the way for your own path to production.
Book Details | |
| Publisher: | Apress |
| By: | Scott Haines |
| ISBN-13: | 9781484274514 |
| ISBN-10: | 1484274512 |
| Year: | 2022 |
| Pages: | 585 |
| Language: | English |
Book Preview | |
| Online | Modern Data Engineering with Apache Spark |
Paper Book | |
| Buy: | Modern Data Engineering with Apache Spark |
Share Modern Data Engineering with Apache Spark